

Merhaba. Offensive Security tarafında yer alan “PEN-200: Penetration Testing with Kali Linux” sertifika eğitimi yazı serisinin on beşinci yazısı olan “Inspecting HTTP Response Headers and Sitemaps” konusunu ele alacağım. Web testleri yaparken incelememiz gereken önemli kısımlardan bir tanesi de HTTP yanıt başlıkları ve sitemaplerdir.
Bu incelemeleri yapmak için Burp Suite veya tarayıcının kendini kullanabiliriz. Biz ilk olarak tarayıcının kendisini kullanacağız. Firefox ile Network tool kullanarak incelemeye başlayalım.
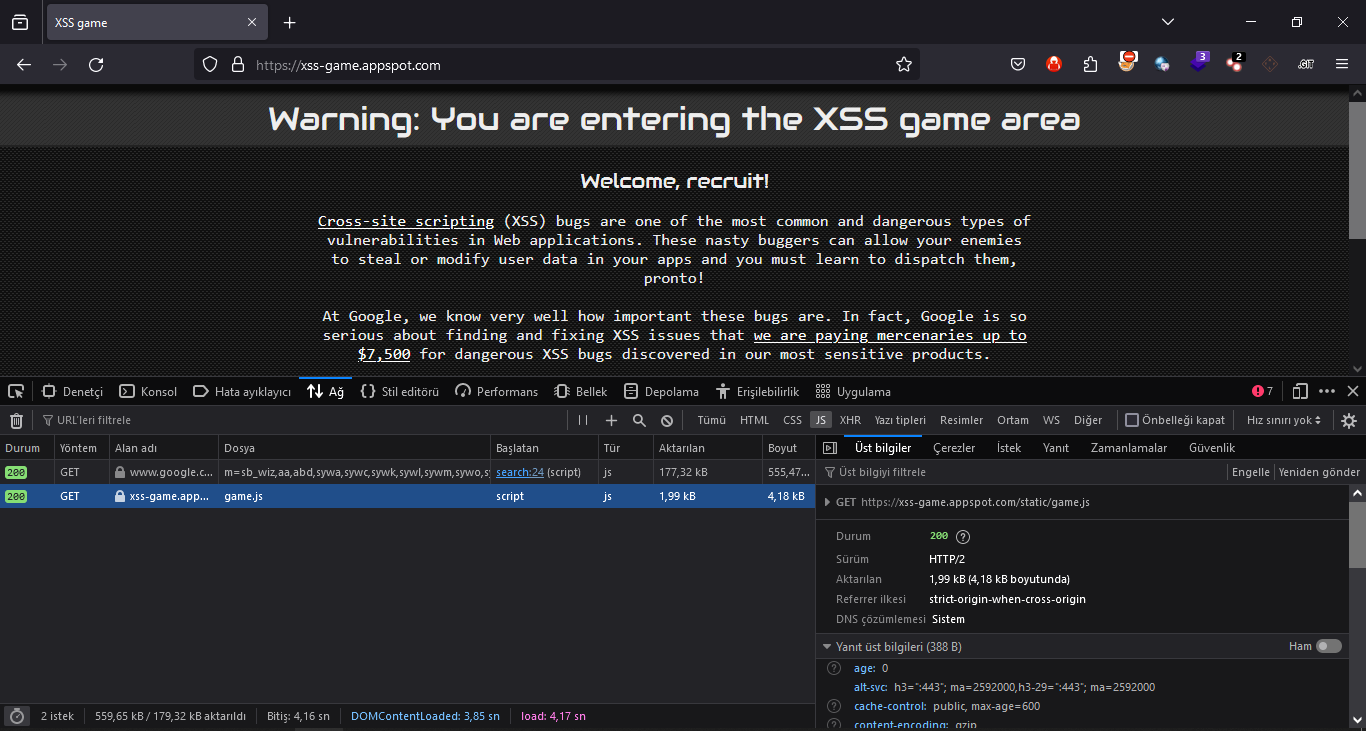
Ağ aracı ile istekleri görebilmek için sayfayı yeniledikten sonra yukarıdaki gibi istekleri görebiliriz. İncelemek istediğimiz isteğe yukarıda görüldüğü gibi tıklayabiliriz.
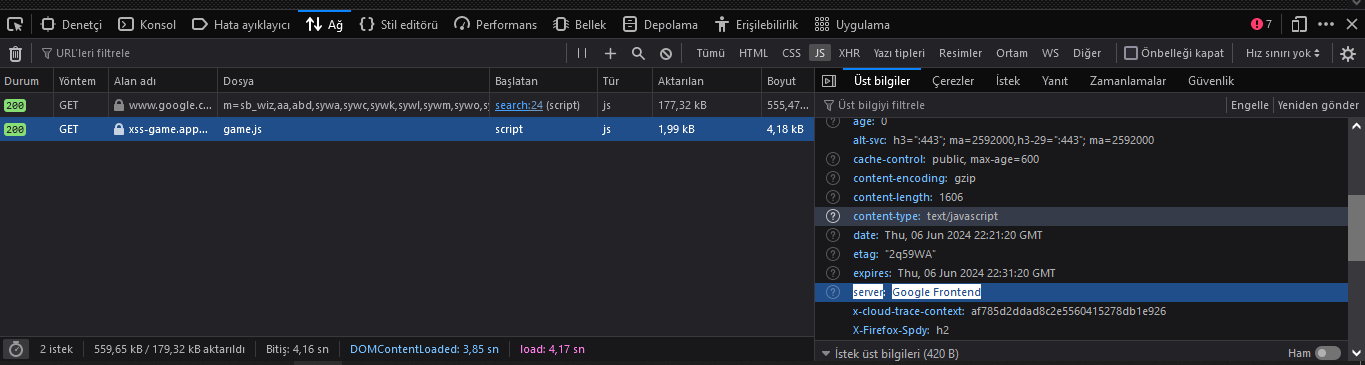
Yukarıda görüntülenen Sunucu (server) başlığı genellikle en azından web sunucusu yazılımının adını ortaya çıkaracaktır. Birçok varsayılan yapılandırmada sürüm numarasını da gösterir.
HTTP üstbilgileri her zaman yalnızca web sunucusu tarafından oluşturulmaz. Örneğin, web proxy’leri, web sunucusuna orijinal istemci IP adresi hakkında sinyal vermek için aktif olarak X-Forwarded-For başlığını ekler.
Yanıt başlığındaki adlar veya değerler genellikle uygulamanın kullandığı teknoloji yığını hakkında ek bilgiler ortaya çıkarır. Standart olmayan üstbilgilerin bazı örnekleri arasında XPowered-By, x-amz-cf-id ve X-Aspnet-Version yer alır. Bu adlarla ilgili daha fazla araştırma yapılması, “x-amz-cf-id” başlığının uygulamanın Amazon CloudFront kullandığını göstermesi gibi ek bilgileri ortaya çıkarabilir.
Site haritaları, web uygulamalarını sıralarken dikkate almamız gereken bir diğer önemli unsurdur.
Web uygulamaları, arama motoru botlarının sitelerini taramasına ve dizine eklemesine yardımcı olmak için site haritası dosyaları içerebilir. Bu dosyalar aynı zamanda hangi URL’lerin taranmayacağına ilişkin yönergeleri de içerir; bunlar genellikle hassas sayfalar veya yönetim konsollarıdır; bunlar tam olarak ilgilendiğimiz türden sayfalardır. Kapsayıcı yönergeler site haritaları protokolüyle gerçekleştirilir; robots.txt ise URL’lerin taranmasını engeller.
Örneğin www.google.com adresinden robots.txt dosyasını curl ile alabiliriz:
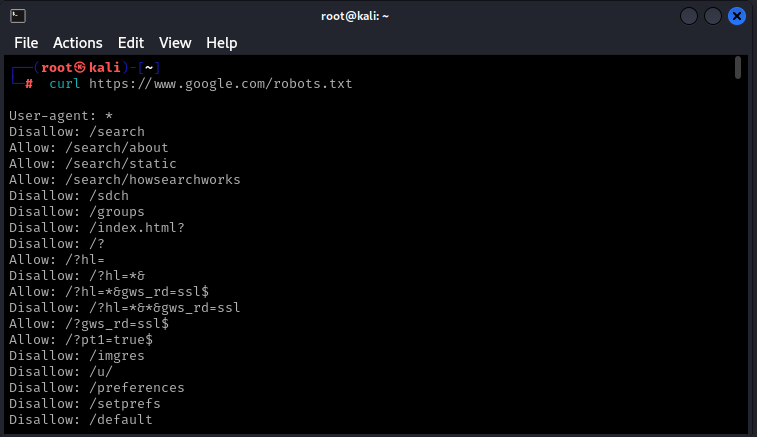
Allow ve Disallow, web tarayıcılarına yönelik, sırasıyla web tarayıcılarının erişebileceği veya erişemeyeceği sayfaları veya dizinleri belirten yönergelerdir. Çoğu durumda, listelenen sayfalar ve dizinler ilgi çekici olmayabilir, hatta bazıları geçersiz bile olabilir. Bununla birlikte, site haritası dosyaları, web sitesi düzeni hakkında ipuçları veya hedefin henüz keşfedilmemiş kısımları gibi diğer ilginç bilgileri içerebileceğinden göz ardı edilmemelidir.
PEN-200 serisinin on beşinci yazısının sonuna geldik. Başka yazılarda görüşmek üzere.

